If You're Cold, They're Cold

The obvious fix to post 4's integration wall was better specs. But the deeper problem was that I didn't have a coherent model for what to spec. I had 16 services, each independently solving cross-cutting concerns in slightly different ways. The complexity wasn't in any single service — it was in the glue.
I picked up Platform Engineering on Kubernetes by Mauricio Salatino looking for a better deployment story. What I found was a framework for managing the complexity of distributed systems — one that large organizations have been refining for years through the CNCF ecosystem. The realization wasn't that I needed better tooling. It was that the tooling already existed and I just needed to understand it.
If You're Cold, They're Cold
Agents are hypersensitive to developer experience. If your DX is painful — if adding a new service means wiring up auth, configuring pub/sub, writing retry logic, setting up health checks — then every agent session inherits that pain. A confusing codebase doesn't just slow you down. It produces worse agent output. An unclear boundary between services doesn't just create technical debt — it creates ambiguous specs that agents interpret in unpredictable ways. If you're cold, they're cold. Bring them inside.
Microservices help draw boundaries. An agent working on a service can't accidentally reach into another service's internals — the boundary is a network call, not a folder convention. But microservices without a platform means every service reinvents the wheel. Each one needs its own auth setup, its own pub/sub client, its own retry logic. That's sixteen opportunities for an agent to make slightly different decisions about the same problem.
The platform eliminates that variance. Before, adding pub/sub to a service meant writing a client, configuring retry logic, managing connection strings, and handling dead letters — four things an agent could get subtly wrong. After, it's a Dapr annotation in the helm chart. When service-to-service authentication is handled by a sidecar, there's no auth code to write and no auth code to get wrong. When rate limiting is a Kong plugin declared in values.yaml, the agent doesn't need to understand rate limiting — it needs to know that the field exists.
The hard thing becomes easy. And easy things are where agents excel.

This isn't about dumbing things down. It's about putting complexity where it belongs. The platform is complex so the slices can be simple. And simple slices mean agents can operate with confidence inside well-defined boundaries.
The Platform and the Slice
The platform handles the concerns that every service needs — identity, networking, observability, messaging, secret management — and each service focuses purely on its domain. A new service shouldn't need to know how mTLS works. It should just have mTLS.
The CNCF ecosystem provides the building blocks. Dapr pushes distributed systems primitives — pub/sub, service invocation, state management, bindings — into a sidecar that sits alongside your service. Your code calls localhost; the sidecar handles the rest. Kong manages gateway concerns declaratively: auth, rate limiting, routing. Network policies enforce boundaries between layers. None of this is application code. It's platform.
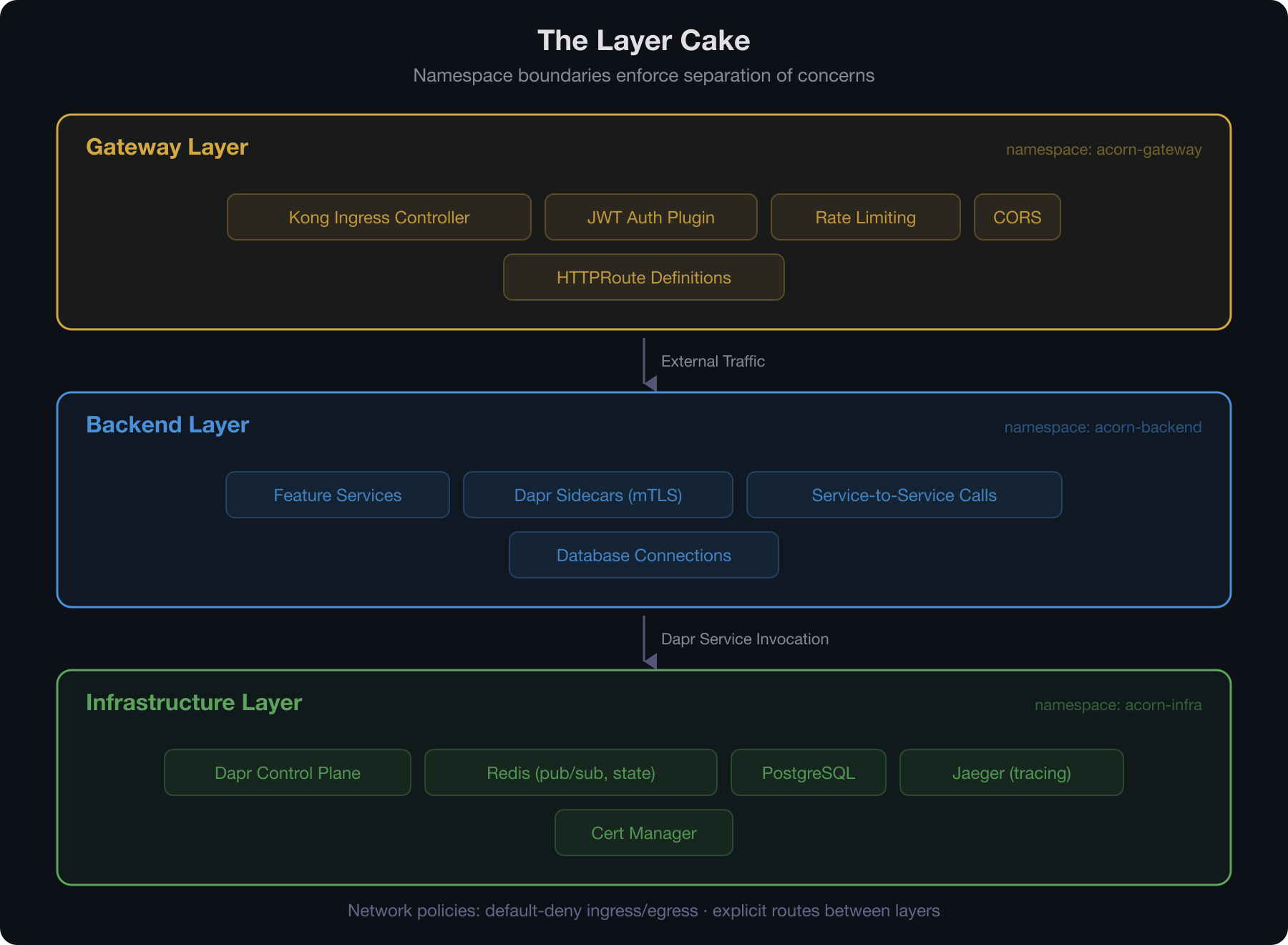
What remains is the vertical slice: a service with its routes, its domain logic, its database schema, and a helm chart that says "I'm a service, here's my port, here are my gateway rules." A library chart fills in everything else — Dapr annotations, health probes, Kong plugins, autoscaling. The contract between platform and slice is the chart's values interface.
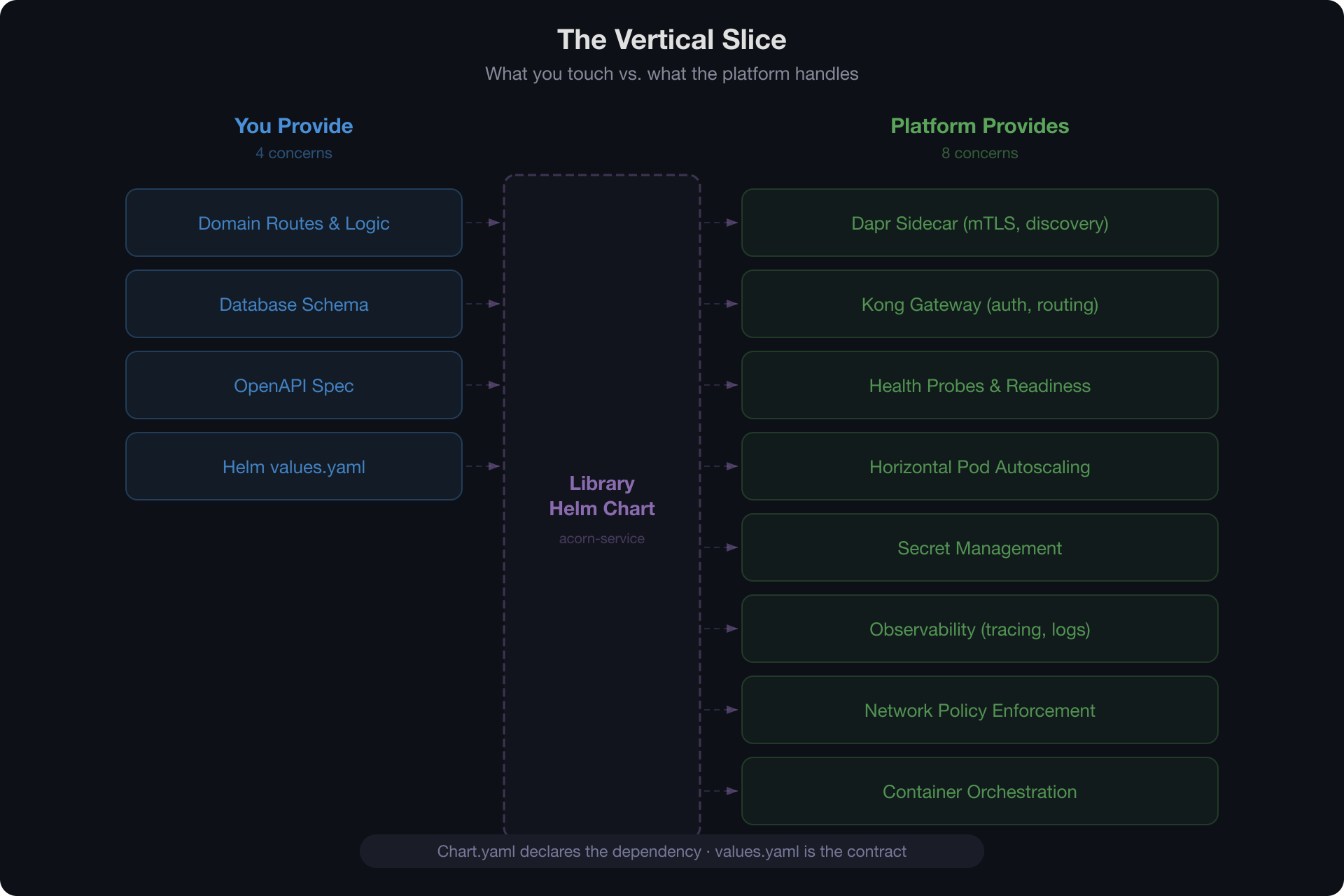
You Have to Do the Reading
None of this works if you don't understand what you're building on. Agents can implement anything you can spec, but you can't spec what you don't understand. Telling an agent "add Dapr pub/sub to this service" is meaningless if you don't know what Dapr pub/sub actually provides — its delivery guarantees, its retry semantics, its component model.
I didn't know any of this six weeks ago. I learned it by reading Platform Engineering on Kubernetes and working through what the CNCF ecosystem offers. Not tutorials — the mental model. What problems does a service mesh solve? Why does a sidecar pattern exist? What's the difference between a binding and a service invocation? Once you have conceptual fluency, you can spec precisely. And precise specs are the entire game.
This is the part that doesn't get automated away. An agent can configure a Dapr component, write a helm chart, wire up Kong plugins. It can't decide that you need Dapr in the first place. It can't evaluate whether your service boundaries are drawn correctly. It can't tell you that the CNCF already solved the problem you're about to build from scratch. That judgment comes from understanding the landscape, and understanding the landscape comes from studying what expert practitioners have already figured out.
The irony is that conceptual understanding goes further than it ever has. You don't need to memorize Lua to write a custom Kong plugin — you need to know that Kong supports custom plugins and what the extension points are. The agent handles the implementation. You handle the architecture.
Standing on Shoulders
Platform engineering used to be the domain of organizations large enough to justify a dedicated team. The tooling was there but the overhead of standing it up wasn't worth it for a small team, let alone a solo developer. That calculus has changed. When an agent can take a well-structured helm chart and produce a fully integrated service in an afternoon, the setup cost of a proper platform amortizes almost immediately.
This has always been a pain point in large systems. What's different is the timeline. In a large org, platform pain surfaces over months and eventually justifies a dedicated team. I hit it in two weeks — and solved it in a weekend. The tooling already existed. I just had to learn what it was for.
Good architecture is good architecture. The distributed systems problems that Dapr, Kong, and Linkerd solve don't care if you have five hundred engineers or one. The difference is that now, one engineer with the right conceptual foundation and the right tools can stand up what previously required a platform team. You just have to know what's possible.
I went looking for a better way to deploy sixteen services. I found a framework for building software that I should have been using all along.