The Job Is the Spec
Here's a ratio that changed how I think about agentic development: 14,128:1.
That's the cache-read-to-input ratio for implementation sessions during the Acorn build. For every 1 token of new input the agent processed, it read 14,128 tokens from cache. What's in that cache? The interface specs. The CLAUDE.md files. The plan documents. The agents aren't remembering a conversation — they're loading my architecture on every turn.
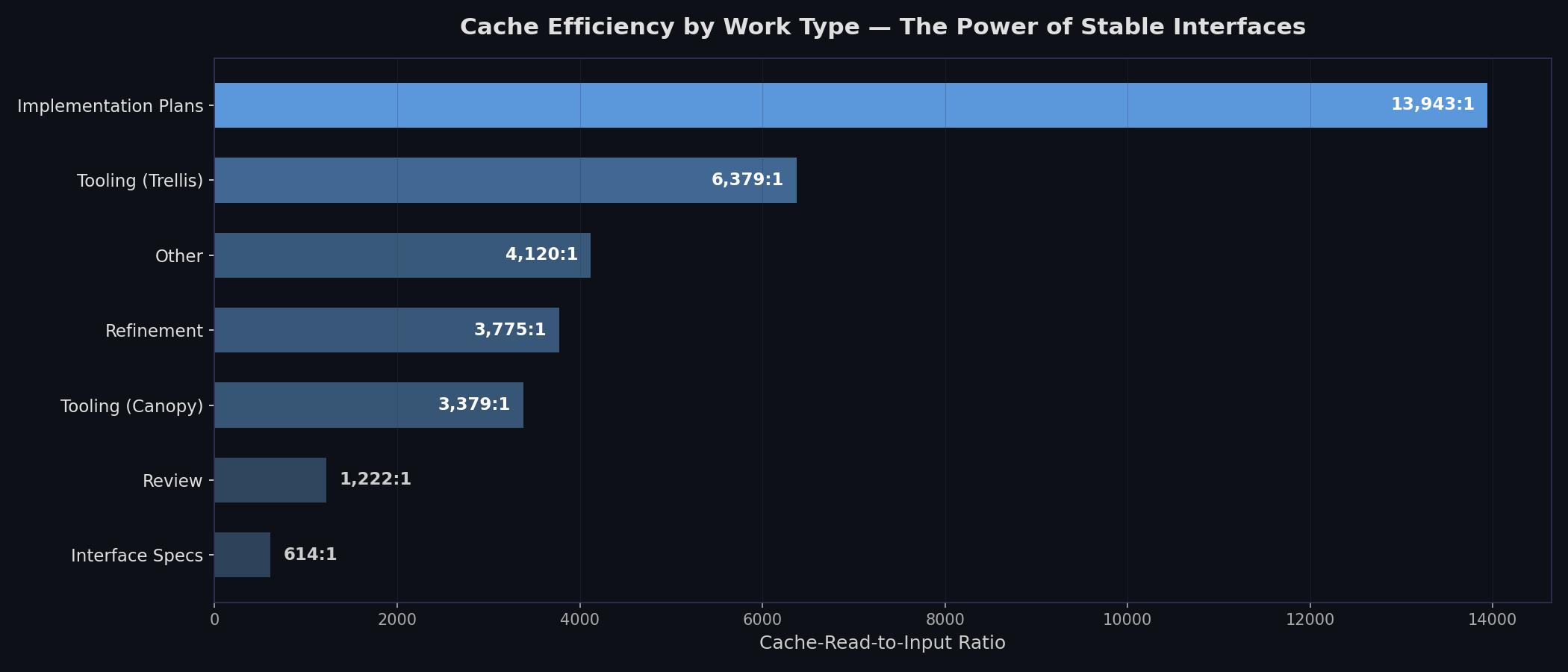
The gradient tells the story. Implementation sessions are the most cache-heavy because the agent is consuming specs it didn't write. Spec-writing sessions have the lowest ratio because you're creating new content, not reading existing architecture. The spec is the shared memory that makes fresh-context sessions work — each agent loads it from cache, builds its piece, and exits. No context pollution. No drift.
There's a cost angle here too. Anthropic charges cache hits at about 10% the rate of non-cache hits, and other providers have similar pricing. I did this project off my Claude subscription so the marginal cost was zero, but for organizations designing software factories, cost matters. A spec-driven approach isn't just more reliable — it's cheaper to run.
So What Do You Say You Do Here
The discipline is specification management: how do you describe your system clearly enough that agents can build it reliably? It means DDL for the data layer, OpenAPI for the API layer, DAGs for the dependency structure, and TypeScript interfaces for the shared types. Each is a format an agent can consume unambiguously. The code becomes a byproduct of this process. The spec is the artifact that determines what the system does.
Without this discipline, agents make their own decisions. Decisions that don't align with your larger project. A developer without a spec will at least ask questions or draw on institutional knowledge. An agent will confidently build the wrong thing. And the gap between "pretty good spec" and "precise spec" gets amplified across hundreds of agent sessions.
I used to spend my days writing TypeScript. Now I spend my days writing specs that describe the TypeScript I want agents to write. The TypeScript is better than what I would have written. The specs are harder than the code ever was.
The Tooling
The immediate problem I ran into was that a 14-repo platform is too much to keep in your head. I needed an organizational system that let me focus on one part of the problem while ensuring it fit with the rest. Nothing out there really aligned with how I wanted to work, so I built my own:
- Canopy — Mission control. A dashboard for managing workspaces, launching worktrees, and visualizing the DAG.
- Trellis — Plan management. Each plan is a markdown directory with inputs, outputs, implementation steps, and dependency edges. An MCP server lets the agent read and update plans directly.
- Grove — Local workspace management. Isolated K8s environments per feature branch.
- Bark — Quality gates. Structured verification that lets you trust agent output without reading every line.
- SAP — Session analytics. Tracks what Claude does so I can tune the process. Also produced the statistics for this series.
I developed all of this in parallel with Acorn itself. I didn't set out to build a development platform, but the state of agentic tooling is still immature enough that rolling your own (especially with agents helping build it) costs less than fighting tools that don't fit your workflow.
I'm certainly not the only person building dependency tracking systems for agents. I built my own because I had a specific vision for how to decompose this project and got value out of designing the interfaces and observability I needed.
In practice, the workflow looks like this. Canopy provides a dashboard of active workspaces:
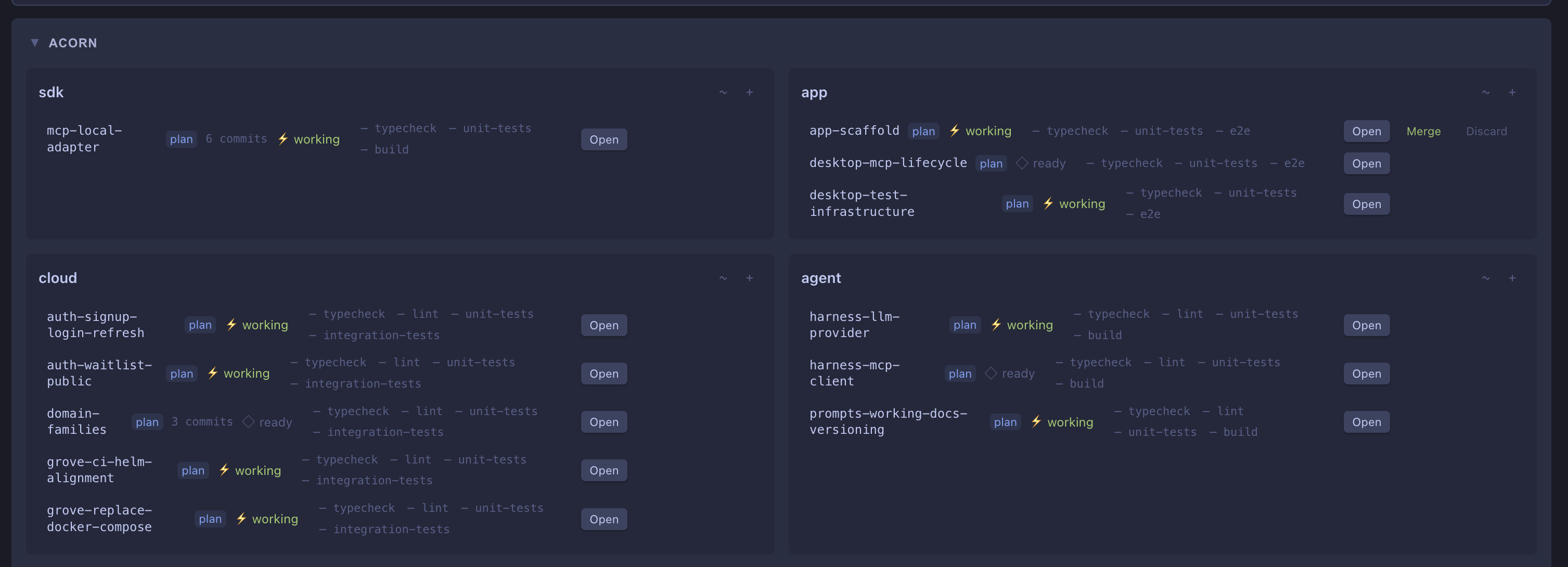
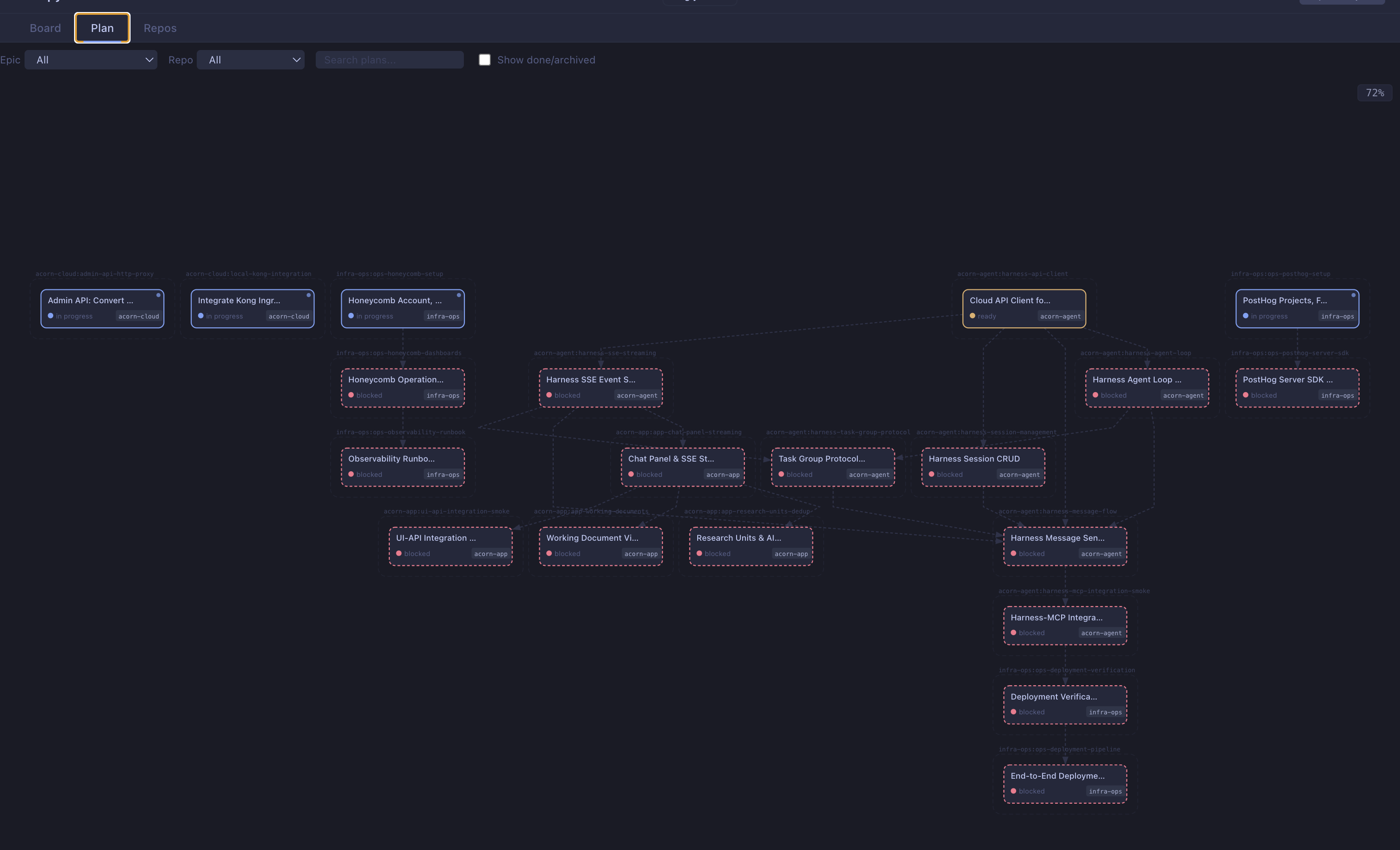
Each box is a repo, each subsection a git worktree. Trellis surfaces what's ready to build next, and the DAG view shows the full project state:
The Shift
Software engineering skills are still critical to this kind of work. But how they're applied changes.
Writing clever TypeScript type inference? Claude can do that. The skill that matters now is decomposition: breaking problems into context-window-sized pieces with clean interfaces. If you design a leaky system, the agent will implement it faithfully, and you'll have a leaky system at scale.
A skill I see becoming increasingly valuable is designing custom tools that help agents comprehend the systems they operate in. By building Trellis, I gave Claude a way to understand the dependencies between parts of the project — its MCP server handled 499 calls during the implementation sprint, letting agents read plans, update status, and check dependencies without human intervention. Building tools for agents is a new kind of leverage — you invest once and every session benefits.
The limitation of agentic development is how well you can specify the system. The value is in the specification, not the code. That's a hard sell to an industry that values code as craft. But the economics are clear: the interface specs, the API contracts, the dependency DAG are the intellectual property. The code is generated output.
We used to turn product requirements into technical implementations. With agents handling most of the coding, technical and product people can collaborate in a common language: the spec itself. Not documentation that sits on a shelf. The shared memory that every agent loads on every turn.